Understanding RAG: What is this thing?
 Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ‘24). Association for Computing Machinery, New York, NY, USA, 6491–6501. https://doi.org/10.1145/3637528.3671470
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ‘24). Association for Computing Machinery, New York, NY, USA, 6491–6501. https://doi.org/10.1145/3637528.3671470
Table of Contents
Large Language Models (LLMs) have swept the world off its feet with its remarkable ability to apparently do almost anything. It is able to perform a wide variety of tasks that were previously considered “human”. From generating coherent text, summarization of documents, and language translation to more complex tasks like creative writing, and reasoning. It is able to do these wonders, to put simply, is because they are fundamentally statistical models that have been trained on an insanely vast amounts of text data.
These models, however, aren’t without limitations. One of the common problem that LLMs face is hallucination where the model produces information that is outdated or incorrect or non-factual. This is where Retrieval-Augmented Generation (RAG) comes to the rescue. In this post, we will go through a TL;DR approach to understanding RAG borrowing information from the survey paper titled “A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models”.
What is RAG?
Without RAG, if you ask the questions like “Who won the last Premiere League?” If the model was not upto date, the conversation might go something like belowUser: Who won the last Premiere League?
Assistant: Manchester City won the Premiere League in 2022
This isn’t wrong but it isn’t what we expected either. We were expecting the answer to be the up to date as Liverpool
Simply put, RAG combines LLMs with an external knowledge retrieval mechanism to fetch up-to-date relevant information without having to retrain the LLM.
What goes into a RAG?
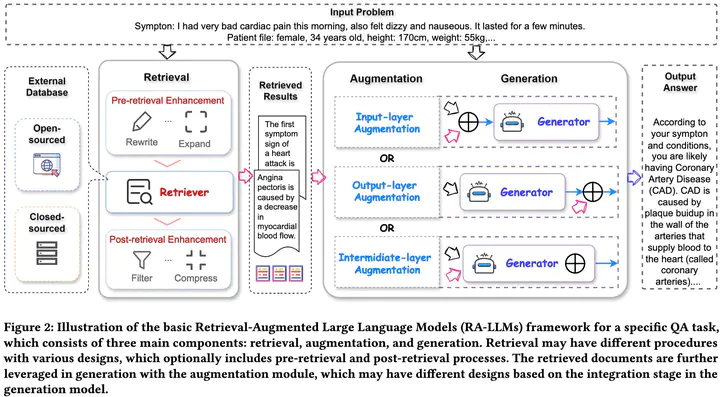
The following figure borrowed from the survey paper shows a detailed illustration of a RAG combined with LLM and what goes into it. It mainly consists of Retrieval, Augmentation and Generation.Retrieval
The main component is the source of information i.e. an external database which can be open-sourced or closed-source stored as a database, document corpus, or vector store. Based on the information and its encoding methods, the retrievals can be sparse or dense.In sparse retrievers, they use word based comparison or embedding like TF-IDF to find similar documents chunks from retriever. We cannot train these as the measures depend on terms as term frequency, document frequency which depends strongly on the quality of documents and query
Contrary to sparse retrievers, dense retrievers first split the query and documents into “chunks” and the chunks can vary from tokens to texts to documents. The chunks are then converted to vector embeddings which will be indexed for retrieval. There are different ways we can train these model to output an embedding which is the main difference between the two. The paper goes into detail of different retriever design which we will skip for now and maybe explore in future posts.
Pre-retrieval and Post-retrieval Enhancement
To ensure the information fetched by the retriever is accurate and relevant, various pre-retrieval and post-retrieval strategies have been proposed. Among the pre-retrieval strategies, there are three broader categories- Query Expansion: The prompt provided by the user is processed by the LLM and using the relevant information obtained from the response by few-shot prompting the LLMs, the query is expanded.
- Query Rewrite: The LLM itself is used to rephrase the query prompts from the user. This step is motivated by the fact that usually, the user prompts are not coherent and there is gap between the input text and the needed knowledge in retrieval.
- Query Augmentation: The original query is combined with the inital generated output to form a new query which is used to further retrieve relevant information.
Post-retrieval enhancement denotes the procedure to process the extracted top-k documents from the retriever before feeding them to the generator
Augmentation
Based on how the retrieved information from the retriever is augmented with the query we getInput-layer Augmentation: Combine the input query and the retrieved information before passing them to generate more coherent response from the generator Output-layer Augmentation: The response from the generator based on the query is augmented with the retrieved information Intermediate-layer Augmentation: The retrieved results are integrated with the internal layers of the generation model. It is most complex among the three and requires knowledge and access to the generation models.
Generation
The design of generators in depends on downstream tasks and can be broadly categorized as white-box (parameter-accessible) or black-box (parameter-inaccessible) models.White-box generators (BART, T5, etc), allow parameter optimization and can be trained to better integrate retrieved information, thereby improving accuracy and relevance in generation tasks. In contrast, black-box generators like GPT, Codex, and Claude do not expose internal structures or parameters, making direct fine-tuning impractical. Instead, they rely on retrieval enhancement strategies discussed above.
After all this, we get the a response that is more coherent and upto date. Coming back to the original question about Premiere League, we then could get an upto date answer
User: Who won the last Premiere League?
Assistant: Liverpool FC won the Premiere League in 2025
Pradeep Bajracharya
PhD Student in Machine Learning
My primary research focus is on Deep Active Learning and its application with Deep Learning on Medical Imaging.